Multi-Time-Point Analysis: A New Way To Analyze Pupil Data
R
eye-tracking
pupil
longitudinal
ML
I walkthrough a technique called multi-time-point analysis highlighted in Yu, Chen, Yang, & Chou (2020)
Introduction
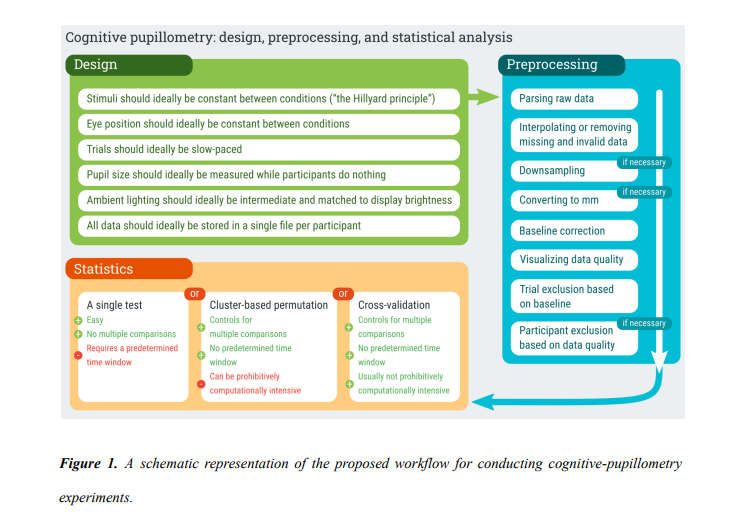
Just a few weeks ago Mathôt & Vilotijević (2022) released a great primer on pupillometry highlighting the method, providing guidelines on how to preprocess the data, and even offered a few suggestions on how to analyze the data (see their great figure below). This paper will for sure be something I revisit and will be the paper I send to folks interested in pupillometry. In their paper, they discuss fitting linear mixed models (LME) together with cross validation to test time points. While I think there are a lot of benefits of this approach (described in their paper), this method does not tell researchers what they really want to know: where an effect lies in the time course. In the the cross-validation + LME approach, it only takes the time points with highest z scores and submits those points to a final LME model. Ultimately, you can say a time point is significant at X, Y, and Z times, but cant really make any claims about the start and end of events. This got me thinking about a paper I read a few years ago by Yu et al. (2020) which looked at a method called multi-time-point analysis which they applied to fNIRS data. I really like the method (and paper) and began thinking about all the ways it could be applied (e.g., EEG, pupillometry). In the paper, they showed that it is a more powerful tool than the often used mass univariate approach. Here I show how to apply this method to pupillometry data.
Multi-Time Point Analysis (MTPA)
There are a wide-variety of options when deciding on an appropriate analysis strategy to use. It is almost impossible to cover every method. When reviewing papers, I feel bad because I inevitable bring up methods the authors did not include. This blog post adds to the already complicated landscape of time course analysis and add yet another tool to the pupillometry toolbox.
I mostly do these blogs as an aid to help me better understand a method. I also hope it will help others.
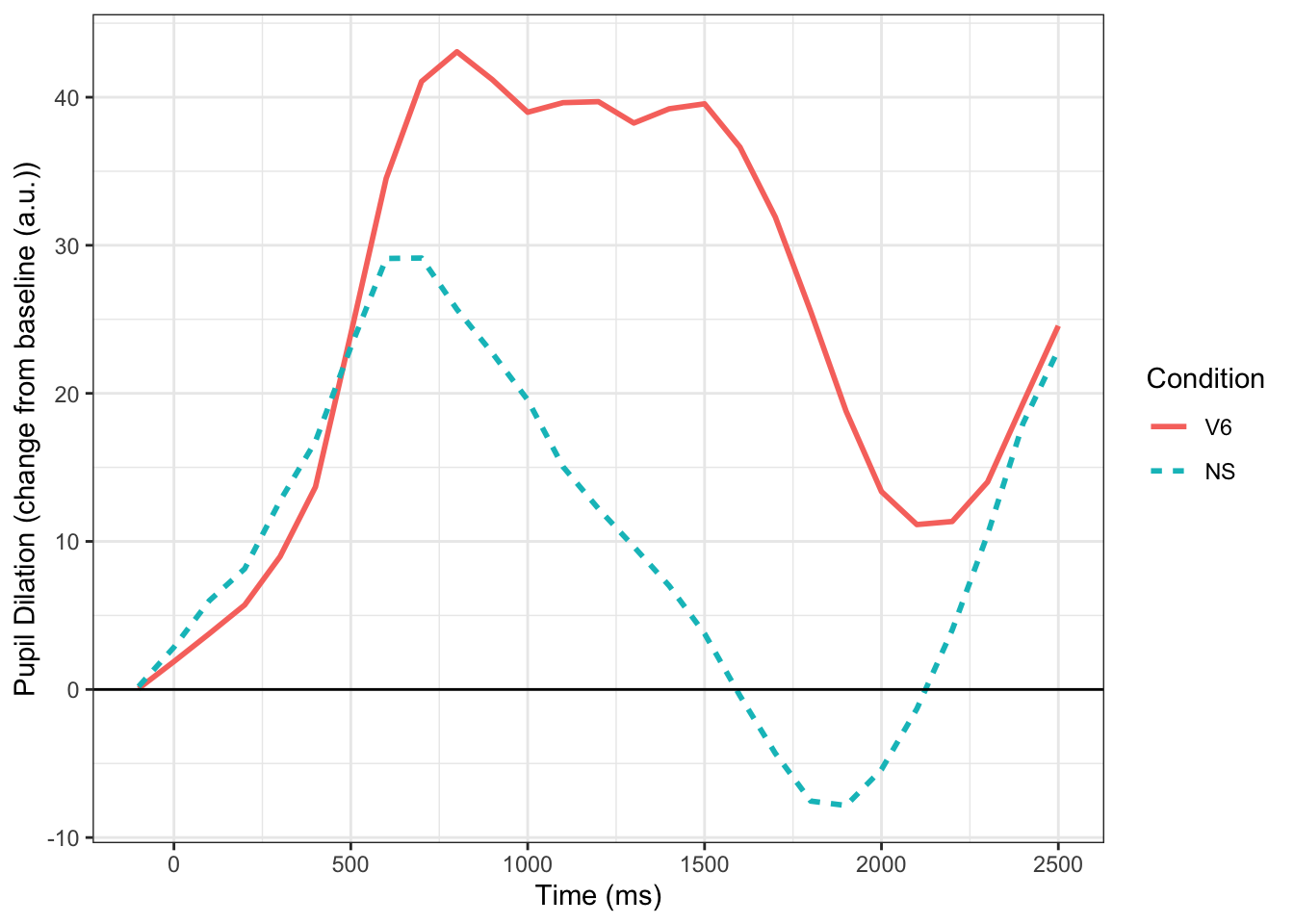
To demonstrate MTPA I am going to use a simple example from data I collected as a postdoc at the University of Iowa. In this experiment, individuals (N=31) heard normal and 6-channel vocoded speech tokens (single words) and had to click on the correct picture. The vocoded condition should be harder, and in the figure below, you can see that it is–larger pupil size throughout the trial. Commonly, we would test significance by using a mass univariate approach (e.g., t-tests at each time point). Below we fit the time course data using Dale Barr’s clusterperm package with no corrections (with corrections nothing is significant). We see that there is a significant difference between the conditions that emerges starting around 800 ms and ends around 1900 ms. Using MTPA would we observe something different?
| timebins | effect | stat | p | p_adjuct |
|---|---|---|---|---|
| 800 | vocoded | -6.729464 | 0.0145280 | 0.0145280 |
| 900 | vocoded | -7.085248 | 0.0123675 | 0.0123675 |
| 1000 | vocoded | -6.560462 | 0.0156954 | 0.0156954 |
| 1100 | vocoded | -8.561962 | 0.0064854 | 0.0064854 |
| 1200 | vocoded | -9.519850 | 0.0043426 | 0.0043426 |
| 1300 | vocoded | -9.398130 | 0.0045664 | 0.0045664 |
| 1400 | vocoded | -10.524933 | 0.0028890 | 0.0028890 |
| 1500 | vocoded | -11.652584 | 0.0018560 | 0.0018560 |
| 1600 | vocoded | -11.458565 | 0.0020007 | 0.0020007 |
| 1700 | vocoded | -11.172190 | 0.0022369 | 0.0022369 |
| 1800 | vocoded | -9.103745 | 0.0051610 | 0.0051610 |
| 1900 | vocoded | -5.687212 | 0.0236102 | 0.0236102 |
Before We Begin: A Summary
Before jumping into the MTPA analysis, I want to explain the method a little bit. The MTPA uses a random forest classifier in conjunction with cross validation to determine if there is a statistical difference in the pupil signal between conditions. This differs slightly from the approach outlined in (Mathôt & Vilotijević, 2022). In their approach, linear mixed models are used in conjunction with cross validation to pick samples with the highest Z value. In contrast, MTPA uses all time points. What MTPA does is calculate the area under the curve (AUC) along with 90% confidence intervals and averages them. Significance is determined by whether the CIs cross the .5 threshold. If it does not, there is a difference between conditions at that time point. Below I will outline specific steps needed to perform MTPA along with the R code.
Running MPTA in R
- We need to read in our sample data (described above) and
pivot_wideso time is in columns and subjects and conditions are long.
### Read Data
# Read the Data preprocessed by gazer
vocode<- read.csv("mtpa_file.csv")
vocode_wide<- vocode %>%
select(-vocoded, -X) %>%
group_by(subject, Condition) %>%
#add T1:27 for time bc weird things when cols are numeric turn condition into factor
mutate(timebins=rep(paste("T", 1:27, sep=""),by=length(timebins)), Condition=as.factor(Condition)) %>%
mutate(expt="pupil", Subject=as.factor(subject), Condition=ifelse(Condition=="NS", 0, 1), Condition=as.factor(Condition)) %>%
ungroup() %>%
select(-subject) %>%
pivot_wider(names_from = timebins, values_from = aggbaseline) %>%
as.data.frame() %>%
arrange(Condition)%>%
datawizard::data_reorder(c("expt", "Subject", "Condition")) %>%
ungroup()- In MTPA, we must first partition the data into bandwidths(here two), or the number of points to consider at a time in the analysis—-for example with a bandwidth of 2, a model would be built from two time points (e.g., 1 and 2 and then 2 and 3 and so on and so forth until the last time point has been fit). In the matrix below, we see that category membership (Related (R) vs. Unrelated (U), or in our case normal and vocoded speech) is predicted from the signal at two time points. This is repeated until the last time point. In our example, this is the 27th time point, or 2500 ms. As a note, Yu et al. (2020) recommend 2 and stated other widths did not result in different conclusions.
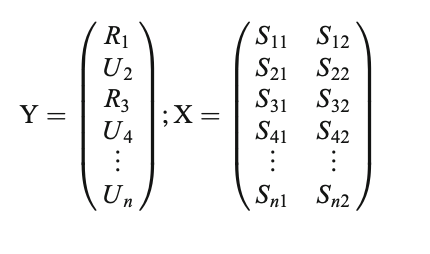
# Define time point starts at -100 and ends at 2500
tp <- seq(-100,2500,by=100)
### Start MTPA
### Set parameters for MTPA
# Consider 2 time points at each testing
binwidth = 2- After this, we set our number of cross validations (100 times here), confidence interval, and our upper (number of time points (here it is 27) - banwidth (2) + 1)) and lower bounds, and create a matrix to store important model results.
- For every time point X CV, we fit a random forest model using the training data we created and use the test set for prediction. It is suggested that you sample 60~70% (two-thirds) of the data to train the model, and use the rest 30~40% (one-third) as your testing set. AUC and other important metrics are calculated for each time point and averaged together and stored in a matrix before going to the next time point. In our example we make sure that an equal number of normal speech and vocoded speech conditions are in each training and test sample.
### Start MTPA model fitting with RF
for (i in lowerbound:upperbound){
# Record the AUC and CE
ceauc <- matrix(NA,4,rcvnum)
# Start cross validation
for (k in 1:rcvnum){
# Set seed for reproducible research
set.seed(k)
# Training and Testing Data
idc_test <- c(sample(1:30,5),sample(31:62,5))
idc_train <- -idc_test
# Fit an RF model
fit <- randomForest(Condition~.,data=vocode_wide[idc_train,c(2,3,(i+3):(i+3+binwidth-1))],importance = F)
yhat_test_prob <- predict(fit,newdata = vocode_wide[idc_test,],type = "prob")[,2]
yhat_test_class <- predict(fit,newdata = vocode_wide[idc_test,],type = "class")
# Record the results of RF fitting on Testing data
ce_test <- mean(yhat_test_class!=vocode_wide[idc_test,]$Condition)
auc_test <- pROC::auc(vocode_wide[idc_test,]$Condition,yhat_test_prob)
ceauc[2,k] <- ce_test
ceauc[4,k] <- auc_test
}
# Store the results of CV
rst_vocode[1,i] <- mean(ceauc[2,])
rst_vocode[2,i] <- mean(ceauc[4,])
rst_vocode[3,i] <- quantile(ceauc[2,],probs = c(ci[1],ci[2]))[1]
rst_vocode[4,i] <- quantile(ceauc[2,],probs = c(ci[1],ci[2]))[2]
rst_vocode[5,i] <- quantile(ceauc[4,],probs = c(ci[1],ci[2]))[1]
rst_vocode[6,i] <- quantile(ceauc[4,],probs = c(ci[1],ci[2]))[2]
}
# Reorganize the results, average all the time points that used to estimate the results
vocodem <- matrix(NA,6,27)
vocodem[,1] <- rst_vocode[,1]
vocodem[,27] <- rst_vocode[,26]
for (i in 1:(upperbound-1)){
tpi <- i + 1
vocodem[1,tpi] <- mean(rst_vocode[1,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
vocodem[2,tpi] <- mean(rst_vocode[2,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
vocodem[3,tpi] <- mean(rst_vocode[3,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
vocodem[4,tpi] <- mean(rst_vocode[4,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
vocodem[5,tpi] <- mean(rst_vocode[5,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
vocodem[6,tpi] <- mean(rst_vocode[6,c((i+lowerbound-1):(i+lowerbound-1+binwidth-1))])
}
vocodem <- as.data.frame(vocodem) # turn into df
colnames(vocodem) <- paste0("Time",1:27) #label time
row.names(vocodem) <- c("CE","AUC","CE_l","CE_u","AUC_l","AUC_u") # label metrics- Finally we transpose the matrix, put time in ms, and plot the AUC at each time point. Where the CIs do not cross the 50% threshold (red dotted line), a significant difference can be said to exist at that time point between conditions.
temp <- as.data.frame(t(vocodem)) # transpose
temp$Times <- tp # turn time into ms
# plot
ggplot(data = temp,aes(x =Times, y = AUC))+
geom_line(size = 1.2)+
geom_ribbon(aes(ymax = AUC_l,ymin = AUC_u),alpha = 0.3)+
theme_bw() +
coord_cartesian(ylim = c(.4, 1)) +
geom_hline(yintercept=.5, linetype="dashed",
color = "red", size=2) +
labs(x="Time(ms)")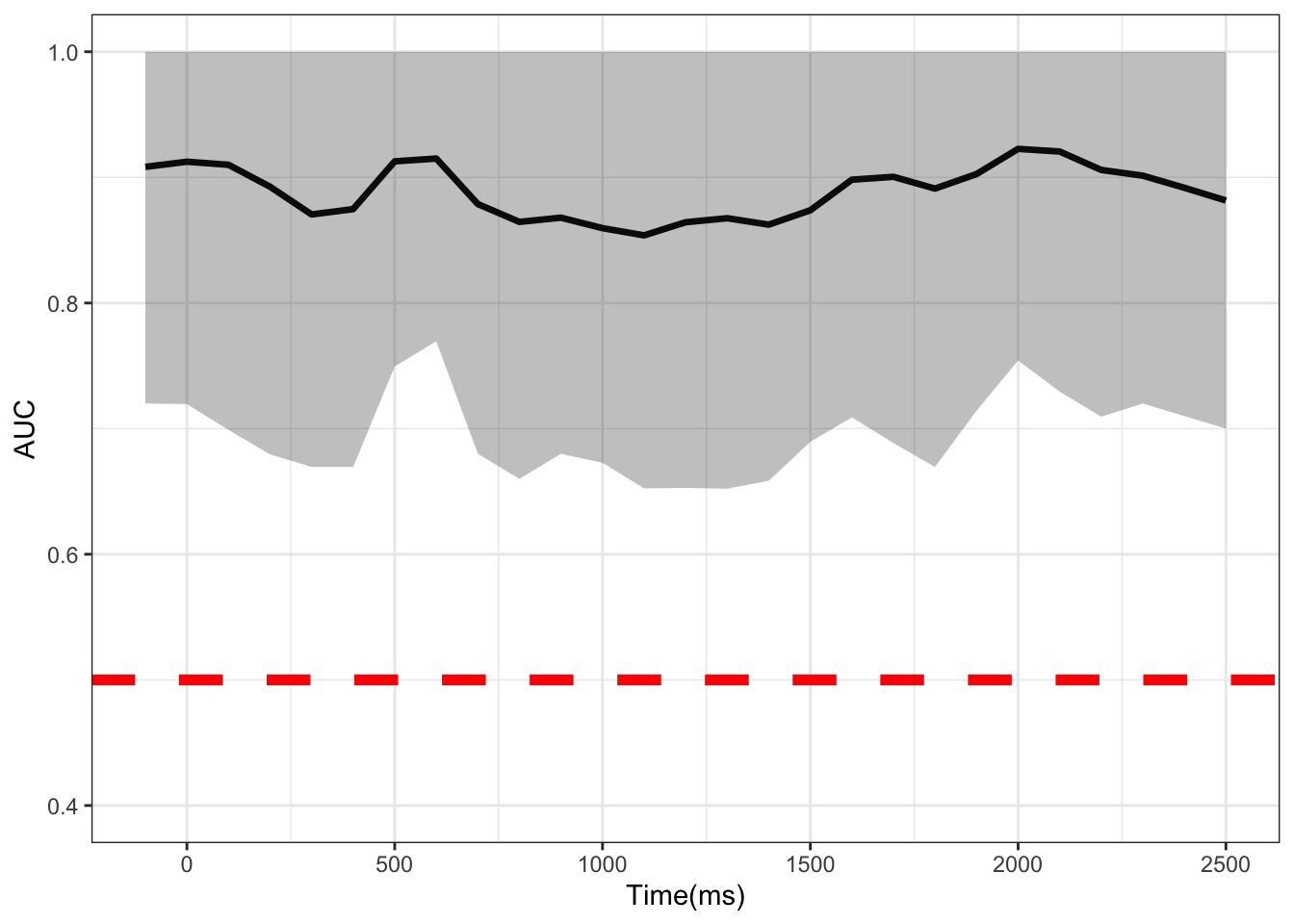
Conclusions
I have shown how to apply MTPA to pupillometric data. This method appears to be more powerful than a mass univariate approach, showing the whole time course as significant. It would be interesting to see how this compares to the method proposed by Mathôt & Vilotijević (2022). I would encourage anyone who is interested in applying this method to also check out Yu et al. (2020)’s excellent paper which this blog is based off of.
Potential Limitations
While this method looks promising, there does appear to be some limitations. First, it look looks like you can’t fit multilevel models. If you can, I suspect it is 1) computationally expensive and 2) not trivial. If anyone has an answer to this I would love to hear it. Second, it appears that you would have to conduct this test for each effect of interest rather then including everything in the model. This is something that Mathôt & Vilotijević (2022) also brings up in their paper. I will have to do some more investigating, but overall I am quite interested in learning more about ML applications to time course data like pupillometry.
R version 4.4.0 (2024-04-24)
Platform: aarch64-apple-darwin20
Running under: macOS Sonoma 14.4
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/New_York
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] clusterperm_0.1.0.9000 gazer_0.1 here_1.0.1
[4] pROC_1.18.5 leaps_3.1 randomForest_4.7-1.1
[7] devtools_2.4.5 usethis_2.2.3 ggthemes_5.1.0
[10] reshape2_1.4.4 boot_1.3-30 crayon_1.5.2
[13] gridExtra_2.3 lubridate_1.9.3 forcats_1.0.0
[16] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[19] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
[22] ggplot2_3.5.1 tidyverse_2.0.0 fdrtool_1.2.17
[25] mnormt_2.1.1 ERP_2.2 pacman_0.5.1
[28] papaja_0.1.2 tinylabels_0.2.4 knitr_1.46
loaded via a namespace (and not attached):
[1] remotes_2.5.0 rlang_1.1.4 magrittr_2.0.3 compiler_4.4.0
[5] png_0.1-8 vctrs_0.6.5 profvis_0.3.8 pkgconfig_2.0.3
[9] fastmap_1.1.1 backports_1.5.0 ellipsis_0.3.2 labeling_0.4.3
[13] effectsize_0.8.7 utf8_1.2.4 promises_1.3.0 rmarkdown_2.26
[17] sessioninfo_1.2.2 tzdb_0.4.0 bit_4.0.5 xfun_0.43
[21] cachem_1.0.8 jsonlite_1.8.8 later_1.3.2 broom_1.0.6
[25] irlba_2.3.5.1 parallel_4.4.0 R6_2.5.1 stringi_1.8.4
[29] pkgload_1.3.4 estimability_1.5 Rcpp_1.0.12 zoo_1.8-12
[33] parameters_0.21.6 httpuv_1.6.15 Matrix_1.7-0 splines_4.4.0
[37] timechange_0.3.0 tidyselect_1.2.1 rstudioapi_0.16.0 yaml_2.3.8
[41] miniUI_0.1.1.1 pkgbuild_1.4.4 lattice_0.22-6 plyr_1.8.9
[45] shiny_1.8.1.1 withr_3.0.0 bayestestR_0.13.2 coda_0.19-4.1
[49] evaluate_0.23 urlchecker_1.0.1 pillar_1.9.0 insight_0.19.10
[53] generics_0.1.3 vroom_1.6.5 rprojroot_2.0.4 hms_1.1.3
[57] munsell_0.5.1 scales_1.3.0 xtable_1.8-4 glue_1.7.0
[61] emmeans_1.10.1 tools_4.4.0 data.table_1.15.4 fs_1.6.4
[65] mvtnorm_1.2-4 grid_4.4.0 datawizard_0.10.0 colorspace_2.1-0
[69] Rmisc_1.5.1 cli_3.6.2 fansi_1.0.6 corpcor_1.6.10
[73] gtable_0.3.5 digest_0.6.35 farver_2.1.1 htmlwidgets_1.6.4
[77] memoise_2.0.1 htmltools_0.5.8.1 lifecycle_1.0.4 mime_0.12
[81] bit64_4.0.5 References
Mathôt, Sebastiaan, & Vilotijević, A. (2022, March 1). Methods in cognitive pupillometry: Design, preprocessing, and statistical analysis. https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zVrwyHMAAAAJ&sortby=pubdate&citation_for_view=zVrwyHMAAAAJ:35r97b3x0nAC
Yu, C.-L., Chen, H.-C., Yang, Z.-Y., & Chou, T.-L. (2020). Multi-time-point analysis: A time course analysis with functional near-infrared spectroscopy. Behavior Research Methods, 52(4), 1700–1713. https://doi.org/10.3758/s13428-019-01344-9
Citation
BibTeX citation:
@online{2022,
author = {},
title = {Multi-Time-Point {Analysis:} {A} {New} {Way} {To} {Analyze}
{Pupil} {Data}},
date = {2022-03-10},
url = {https://www.drjasongeller.com/blog/posts/2022-03-10-mtpa-pupil/},
langid = {en}
}
For attribution, please cite this work as:
Multi-Time-Point Analysis: A New Way To Analyze Pupil Data.
(2022, March 10). https://www.drjasongeller.com/blog/posts/2022-03-10-mtpa-pupil/